Merge
Overview⚓︎
Merge is a data lifecycle service that organizes Hydrolix data into an optimal state. A merge process runs continuously in Hydrolix clusters.
Hydrolix can ingest data out of order. Because Hydrolix makes data available quickly, out-of-order ingestion can initially create sub-optimal partitions. This sub-optimal partition structure can lead to inefficient compression and performance.
Architecture⚓︎
The merge-controller service communicates with merge-peer pools directly over gRPC without any intermediate queue.
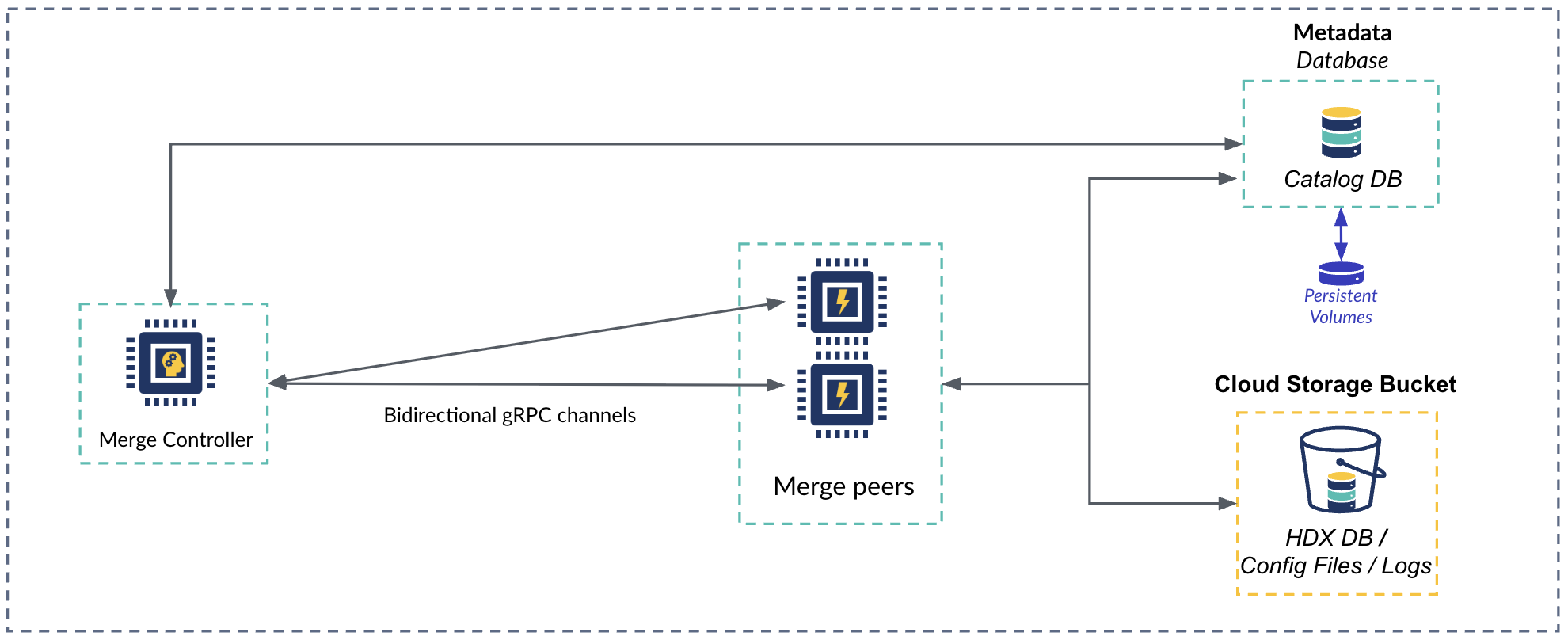
| Component | Description | Scale to 0 |
|---|---|---|
| Merge controller | Determines which partitions to combine to improve query performance and storage costs. Communicates merge tasks to merge peers over gRPC. | Yes |
| gRPC channel | Direct connection between merge controller and merge peers. | Yes |
| Merge peer | Workers that take partition combine tasks from the merge controller. Reads partitions from storage and combines them into new partitions. Writes new combined partitions to the Hydrolix database and updates the catalog. | Yes |
| Hydrolix database storage bucket | Contains the partitions that comprise the database. Part of the core infrastructure. | No |
| Catalog | Contains metadata about data stored in Hydrolix. Part of the core infrastructure. | No |
🛠️ Configure Merge
To configure Merge in your Hydrolix cluster, see Merge.
Related information⚓︎
- The Hydrolix Merge Service: Continuous Optimization at Scale - Overview of how merge continuously improves partition layout for query performance and storage efficiency
- The Hydrolix Merge Service: A Deep Dive - Detailed look at merge algorithms, partition scoring, and tuning strategies